In my last post I described a way to ingest Kafka messages into Zabbix, this method used kcat to poll the Kafka bus. In this post I share two other methods:
- Python: Polling a Kafka topic with a Python consumer script (via Zabbix user parameter)
- Logstash pipeline: Subscribing to a Kafka topic with Logstash and leverage the Zabbix output plugin
By integrating Zabbix with a messaging system such as Kafka, you unlock the ability to subscribe to and interpret messages, enabling the capture of performance statistics and information provided through these messages.
Polling versus Subscribing
Imagine Polling like walking every hour/minute to your mailbox to see if there is new mail, and Subscribing like some automated way to deliver new mail directly to your brain.
When polling, you are by definition not directly informed. Next to that, if you only poll for the latest message in the topic, any intermediate messages will be missed.
This results in missing metrics, or evaluating the same message multiple times. So, take note of this when configuring your Kafka workflow/pipeline. It is up to you and the use case if this is a problem or not.
Method 1: Python Consumer Script
Using the python-way, Zabbix executes a “User Parameter” on a Zabbix Agent. What this does is execute a Python script with a given interval. The scripts connects to the Kafka topic and finds the latest message. The message is then returned as JSON to Zabbix.
The sections below explain each individual component.
Components
This method uses the following components:
- Zabbix Template that contains at least:
- Master Item
- Dependent Items
- Zabbix Agent User Parameter configuration on the machine that will poll the Kafka topic
- Python script
Zabbix Template
The Zabbix Template consists of a master item that polls the Kafka Topic that contains the IoT messages. A master item is like a regular Zabbix Item, it is only referenced as a master item on other items. This way every time the master item runs, every dependent item runs at the same time.
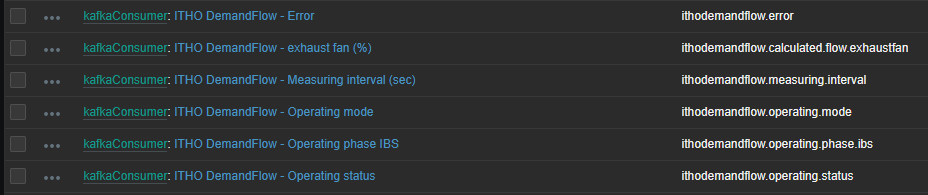
In the following screenshot you see kafkaConsumer. This is the item that polls for Kafka messages in the configured topic. You also see kafkaConsumer: ITHO * items. These items will be executed every time kafkaConsumer runs.

In this case kafkaConsumer runs every minute -> gets the latest message -> the message gets dissected by dependent items, that extract their relevant piece of information from the message -> the result is stored in the Zabbix database.
Zabbix Agent User Parameter
A User Parameter in Zabbix is a custom item that allows you to define specific data collection commands on the monitored host, enabling the collection of unique or custom metrics not natively supported by Zabbix agents.
The Zabbix Agent configuration is stored in: /etc/zabbix/zabbix_agentd.d/scripts/kafkaConsumer.py
UserParameter=kafkaConsumer,python3 /etc/zabbix/zabbix_agentd.d/scripts/kafkaConsumer.py
Python script
The python script is stored in:
/etc/zabbix/zabbix_agentd.d/scripts/kafkaConsumer.py
This script requires the kafka-python plugin:
pip install kafka-python
import json
from kafka import KafkaConsumer, TopicPartition
topic_name = 'itho-metrics'
bootstrap_servers = 'kafka.greypixel.nl:9092'
# Kafka Consumer
consumer = KafkaConsumer(
bootstrap_servers=bootstrap_servers,
auto_offset_reset='latest', # Start reading at the latest message
enable_auto_commit=False, # Disable auto commit to improve performance
value_deserializer=lambda m: json.loads(m.decode('ascii'))
)
# Directly assign the consumer to the topic partition instead of subscribing
partitions = consumer.partitions_for_topic(topic_name)
topic_partitions = [TopicPartition(topic_name, p) for p in partitions]
consumer.assign(topic_partitions)
# Seek to the end of each partition to get to the latest message
for tp in topic_partitions:
consumer.seek_to_end(tp)
# Consume the latest message
consumer.poll(timeout_ms=1000)
for tp in topic_partitions:
# Seek to one before the last message if there is one
position = consumer.position(tp)
if position > 0:
consumer.seek(tp, position - 1)
message = next(consumer)
print(json.dumps(message.value, indent=4))
# Close the consumer
consumer.close()
Master Item
The Master Item leverages the above mentioned User Parameter. In this case it is called kafkaConsumer with a key value kafkaConsumer. The key value is the information that is requested from the Zabbix Agent, and must be named like the User Parameter in the step above. The agent then executes the user parameter (the Python script in this case) to get the latest message from the Kafka topic.
The returned information is JSON, which is stored as text, so set Type of information accordingly.
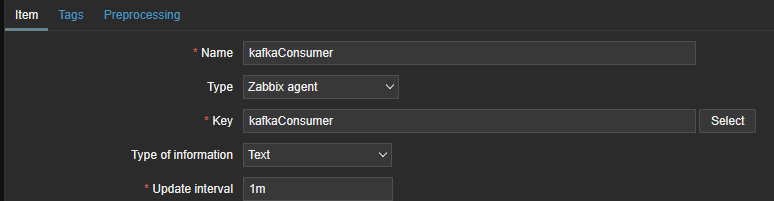
Dependent Items
The Dependent Item, configured with a specific Type, uses the kafkaConsumer item as its Master Item. Through preprocessing, it extracts the relevant value from the results obtained by the Master Item. This is also where you configure data retention in the Zabbix database, in this case 365 days for history and 10 years for trends.
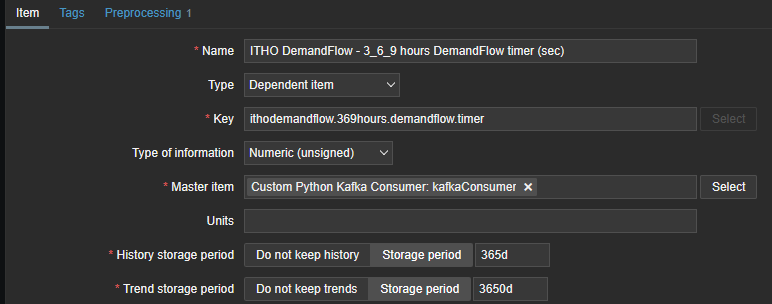
In Preprocessing you configure the value that must be extracted by specifying a JSONPath. This parses the JSON message and gets the relevant information. The type of information is set to Numeric in this case, but that depends on the value range that is expected.
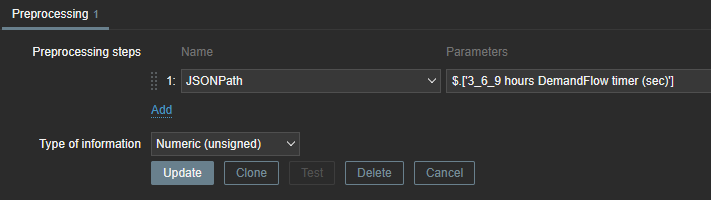
Continue doing this for all metrics/values that you want to extract from the JSON message.
Checking the results
The polled and parsed information is now visible in the “Latest data” view in the Zabbix console:
Method 2: Logstash
This method is a bit more complex but more versatile. The complexity mainly comes from adding Logstash in the Kafka-Zabbix mix…but it creates a lot of possibilities for log management and routing.
What is Logstash?
Logstash is a lightweight, open-source, server-side data processing pipeline that allows you to collect data from various sources, transform it on the fly, and send it to your desired destination. It is most often used as a data pipeline for Elasticsearch, an open-source analytics and search engine.
It can be extended with plugins, in this case we use the Kafka and Zabbix plugins.
The installation and initial configuration of Logstash is out of scope for this post. I only share the Kafka/Zabbix pipeline specifics.
Components
This method uses the following components:
- Logstash
- Logstash plugins
- Logstash Pipeline
- Kafka Input
- Zabbix Output
- Zabbix Template
Logstash Pipeline
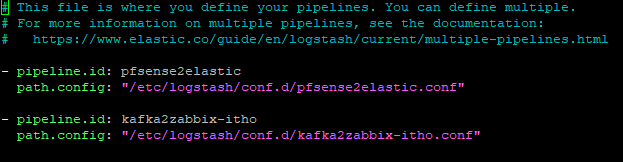
Create a new Logstash pipeline by editing pipelines.yml
Logstash Zabbix output plugin
This pipeline uses the Zabbix output plugin to send data to Zabbix.
It is installed by: bin/logstash-plugin install logstash-output-zabbix
Sending a single item
Next to the message itself the plugin needs a Zabbix Host and Item specified as fields. The data is sent to Zabbix and stored on the specified Item in the Zabbix DB.
In this example I use the Single Item approach, and extract the values in Zabbix using pre-processing.
Sending multiple items
The plugin can also accept multiple values when using the multi_value field. This way you will need to provide an array of values (key/value pairs). In this case all filtering is done in the Logstash pipeline.

If you want to know more about the plugin, it is documented here.
Logstash Pipeline configuration
This is the configuration file of the pipeline.
It is stored as: /etc/logstash/conf.d/kafka2zabbix-itho.conf
input {
kafka{
bootstrap_servers => "kafka.greypixel.nl:9092"
topics => ["itho-metrics"]
id => "kafka_input"
}
}
filter {
mutate {
add_field => {
"zabbix_host" => "logstashkafka"
"zabbix_key" => "itho-metrics"
}
}
}
output {
zabbix {
zabbix_server_host => "zabbix.greypixel.nl"
zabbix_host => "zabbix_host"
zabbix_key => "zabbix_key"
id => "zabbix_output"
}
}
Input
What this does is subscribing to the Kafka topic and grabbing messages as they pass by. It needs to know the Kafka broker server name and port, and the topic you want to subscribe to.
I also added an ID:

Filter
In the filter block, two fields are added:
- Zabbix Host – This is the host that holds the item.
- Zabbix Item – This is the item that will hold the data.
Output
The output sends the information to Zabbix by the trap mechanism, much like what the Zabbix Sender does.
Notice the zabbix_host and zabbix_item configuration. These items must exist in Zabbix for the data to be delivered. Please note that you can not configure the values for the host and item in this block. They must be added as fields in the filter (or earlier in the pipeline).
Like in the input, I added an ID to make the logging easier to understand.
Zabbix Template
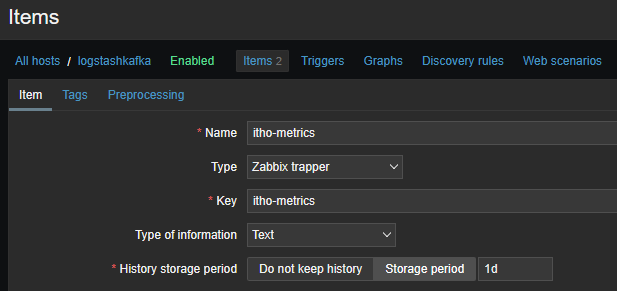
The Zabbix Template contains an Item with the following configuration. Note the key name, this must match the value for zabbix_key in the Logstash pipeline. The type of the item must be zabbix trapper.
Zabbix Host
For the host you can use an existing host, or one that is specifically created for this use case. The name must be as configured in the Logstash pipeline.

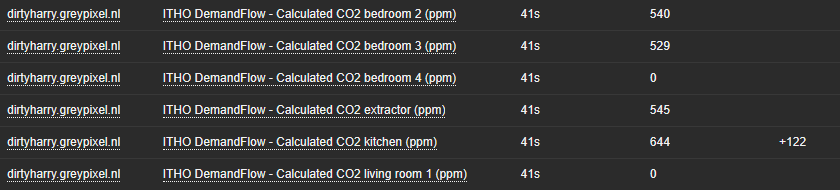
Checking the results
The polled and parsed information is now visible in the “Latest data” view in the Zabbix console:

Conclusion
This post described two alternatives to the kcat method I posted earlier. Personally, I like the Logstash way the best, it is more versatile and can be used in a lot of other ways (more control, filtering en connecting with other tools). I also prefer the “subscribing” that the Kafka input for Logstash does…it listens for new messages rather then polling using a fixed interval.
One of the drawbacks of polling is that you can miss information. Polling uses an interval that probably is out of sync with the rate that Kafka messages are produced. It depends on the use case if that is a problem.
Now we have three ways of connecting Zabbix to Kafka. Monitoring, just do it!
A version of the mentioned Zabbix template can be found here: GitHub